If you follow discussion on running cloud native, monolithic or more traditional applications you may have stumbled over the terms “scale up“ and “scale out“. Don’t feel bad if you don’t know these, because they were formerly just “vertical scaling“ (scale up) and “horizontal scaling“ (scale out).
What is scale up?
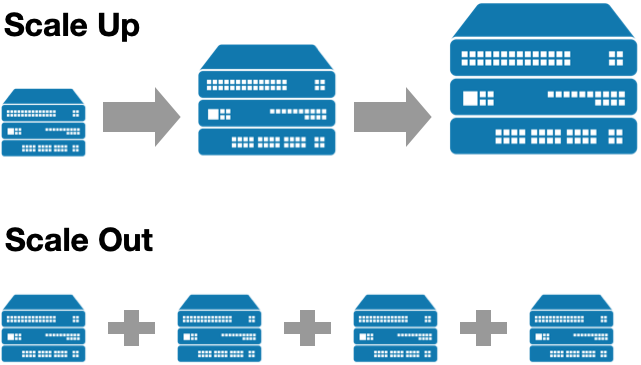
Scale up means, if you have e.g. a server in your datacenter running your database, to make the database faster or have more concurrent client getting served, you would add more hardware to that server and just make it the biggest machine available.
This approach works and there might be good reason to do it, it’s relatively easy to do because you just buy more RAM, bigger processors, disks or network cards, you will not have to modify your application to have higher performance, it may not even be your task, but you can (t)ask other teams or your provider to do it for you. It may be expensive, because the beefiest machine mostly is also the most expensive machine, with the latest and greatest CPUs, etc.
The drawback though is that once you upgraded to the biggest, beefiest machine, you can not scale any further, it will be hard to move to a new machine, because that means, right, moving off that machine and probably have planned downtime (i recommend to read this Stackoverflow post about migrating their DB clusters that talks to the pain they have been experiencing).
Scale out 101
On the contrary, there is that concept of „scale out“ aka horizontal scaling that had a lot of coverage over the last years with the rise of Googles compute model, clouds and cloud native applications. What does scale out mean?
Scale out in our above example would mean to put the database workload on more machines instead of running a bigger machine and build a cluster of machines that can be cheaper than your big server.
Scaling out gives you a way to work with cheaper hardware, while at the same time you gain redundancy and resilience to failure, because there’s always nodes that still have the data. You will also be able to scale beyond a single location because it would not matter to the database clustering and replication if those replicas are distributed around the world.
Database getting too small - add more. You can even do this dynamically and scale out only in times of extreme load, this is what autoscaling does for you. When your system load lowers, just get rid of those instances.
It will also help you to not spend all your money on the most expensive piece of hardware and plan too much ahead in terms.
Scale out is a recipe for scalability and resilience and flexibility as can be seen with cloud native applications, companies, software patterns, etc.
Scaling out segmentation
The above approach hasn’t really been used much in security segmentation. If there is a datacenter firewall that segments your DMZ and datacenter, it usually is a single firewall cluster with several interfaces. The more bandwidth and the bigger the interfaces, the more expensive this gets and people usually overcommit because the aggregated bandwidth of the connected devices will be much higher than the interface bandwidth that connects a zone or a bunch of machines in a vlan.
If you think how you could scale this out instead of scaling it up (buy a bigger firewall and buy a bigger one in 2 years and buy a bigger…), it’s clear that this is a great solution for the firewall vendors, because they will make a lot of money with their biggest firewalls.
If you imagine you could scale this out you would probably use more firewalls, that could be cheaper, it would still have some issues like you would need to orchestrate policy for all of those hardware firewalls, you would introduce single points of failure (so you would need to cluster more firewalls and operate those firewall clusters), and you would have a HUGE operational overhead to cope with the complexity of operating many firewalls and establishing policy across a army of firewalls.
There is another approach how to do this and it moves visibility and enforcement closer to the data and uses existing firewalls that you already have, and you have many of them. It is the firewall on each of your datacenter servers, VMs, IaaS instances, even the firewalls on your k8s nodes. You just never used them because of the above operational burden of operating many firewalls at once.
This is what host-based solutions are doing and this is the only segmentation strategy that can scale massively on any deployment factor like bare metal, VMs, IaaS and even containers and at the same time enforce fine-grained policies down to the process level because the firewall is sitting so close to the data. This might be hard to swallow for us networkers, because we have been doing our hardware, firewall, switch, zone and VLANs thing for so long, but it gives us all the above plus it will make you independent of the underlying network because now enforcement can happen where the data flows are initiated instead of blocking them in choke points somewhere in your network.
This article was previously published on LinkedIn.
